Look Ma, No Hands! Agent-Environment Factorization of Egocentric Videos
|
Matthew Chang
|
Aditya Prakash
|
Saurabh Gupta
|
|
UIUC
|
UIUC
|
UIUC
|
The analysis and use of egocentric videos for robotic tasks is made challenging by occlusion due to the hand and the visual mismatch between the human hand and a robot end-effector. In this sense, the human hand presents a nuisance. However, often hands also provide a valuable signal, e.g. the hand pose may suggest what kind of object is being held. In this work, we propose to extract a factored representation of the scene that separates the agent (human hand) and the environment. This alleviates both occlusion and mismatch while preserving the signal, thereby easing the design of models for downstream robotics tasks. At the heart of this factorization is our proposed Video Inpainting via Diffusion Model (VIDM) that leverages both a prior on real-world images (through a large-scale pre-trained diffusion model) and the appearance of the object in earlier frames of the video (through attention). Our experiments demonstrate the effectiveness of VIDM at improving inpainting quality on egocentric videos and the power of our factored representation for numerous tasks: object detection, 3D reconstruction of manipulated objects, and learning of reward functions, policies, and affordances from videos.
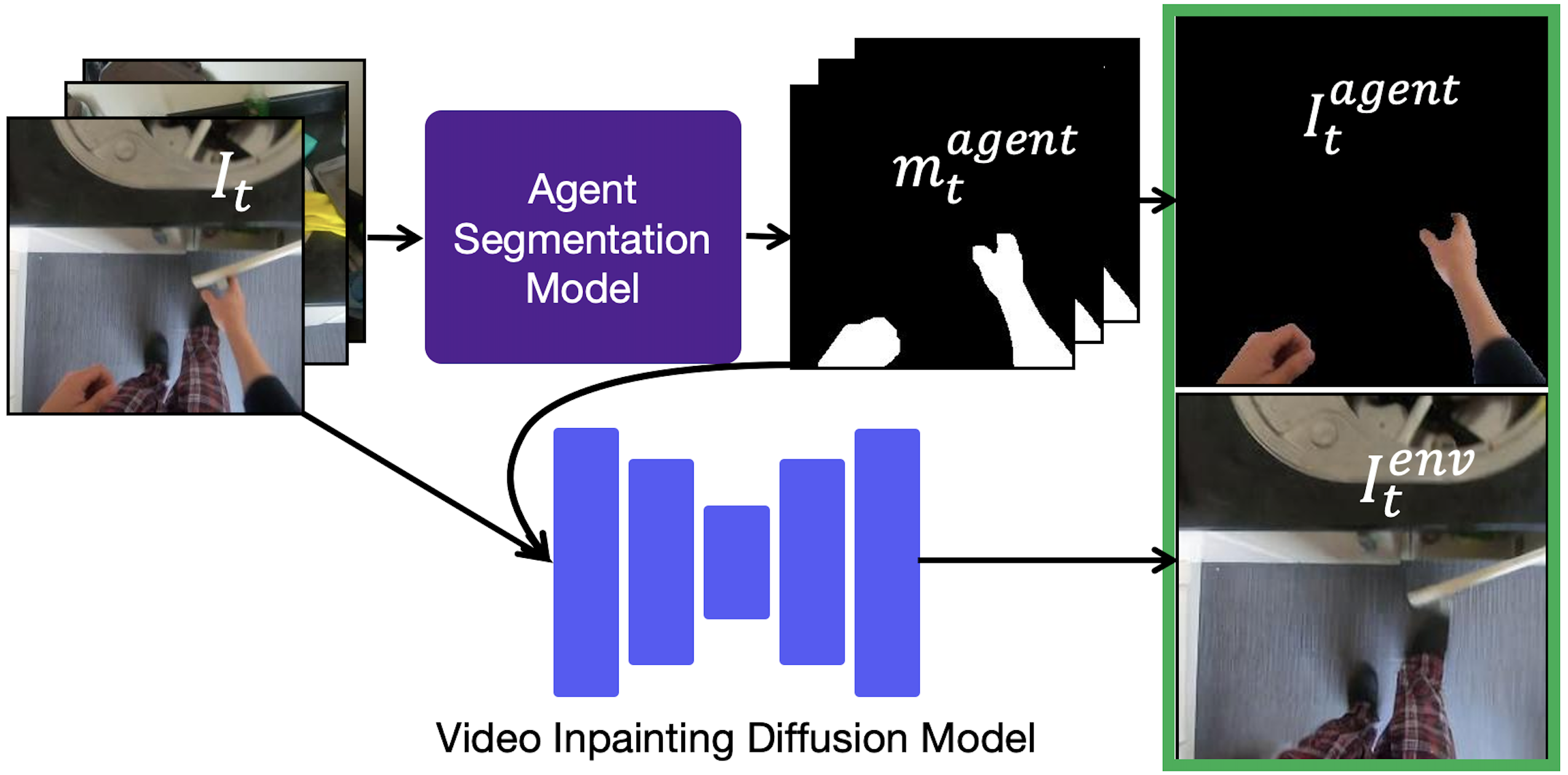
Agent-Environment Factorization of Egocentric Videos
Occlusion and the visual
mismatch between humans and robots, make it difficult to use egocentric videos for robotic tasks. We
propose a pixel-space factorization of egocentric videos into agent and environment representations. An agent representation is obtained using a model to segment out the agent. The environment representation is obtained by inpainting out the agent from the original image using VIDM, a novel Video Inpainting Diffusion Model.
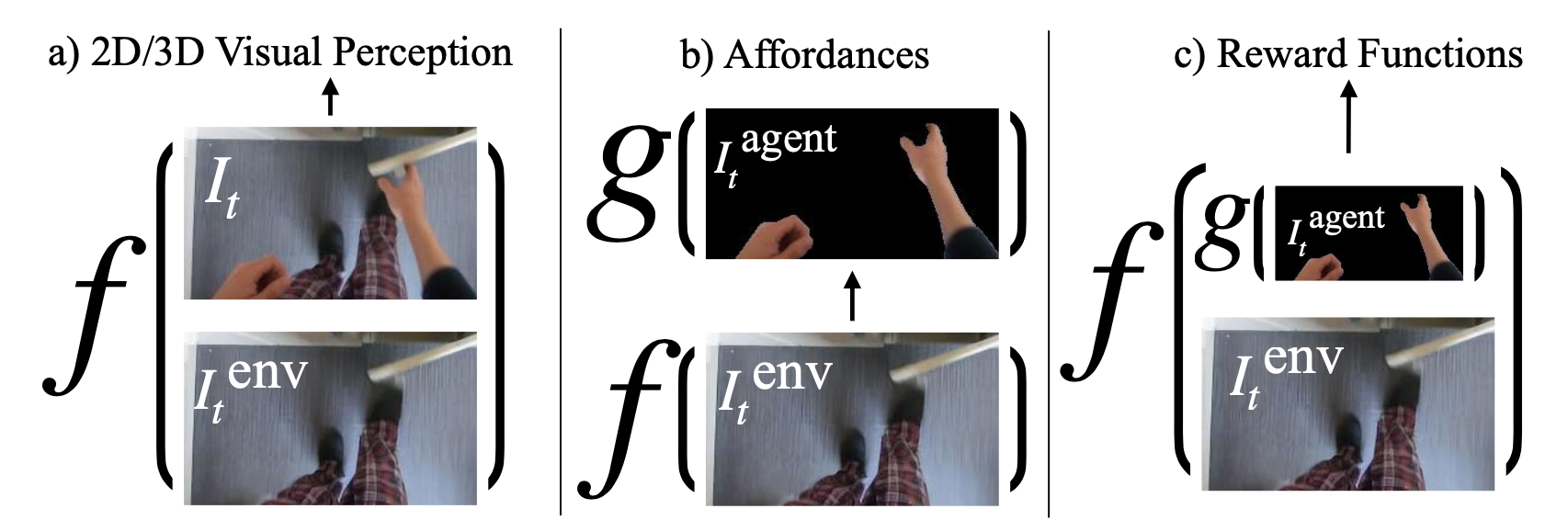
Applications of Agent-Environment Factorizations
Agent-Environment Factored (AEF) representations enable many applications. (a) For
visual perception tasks, the unoccluded environment can be used in addition to the original image.
(b) For affordance learning tasks, the unoccluded environment
can be used to predict relevant desirable aspects of the agent.
(c) For reward learning tasks agent representations can be transformed into agent-agnostic formats for more
effective transfer across embodiments.
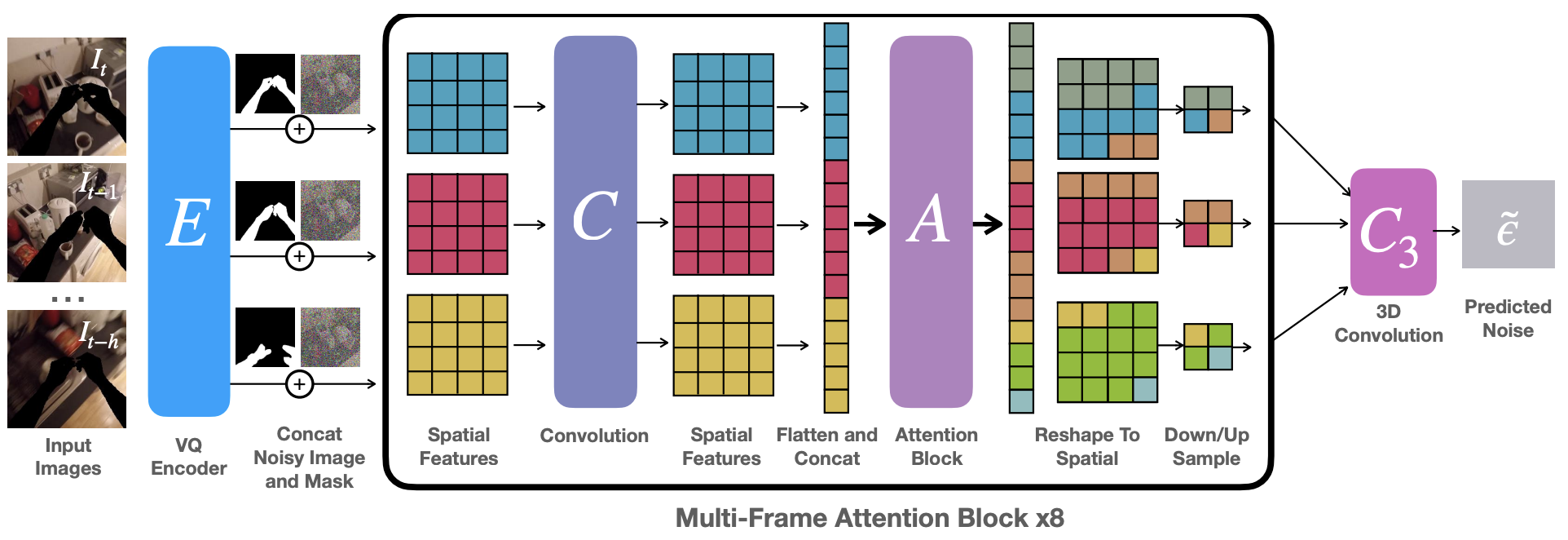
Video Inpainting Diffusion Model (VIDM)
We extend pre-trained single-frame inpainting diffusion models to videos. Features from context frames are introduced as additional inputs into the Attention Block A. We repeat the multi-frame attention block 8 times (4 to encode and 4 to decode) to construct the U-Net that conducts 1 step of denoising. The U-Net operates in the VQ encoder latent space.
Paper

|
|
Matthew Chang, Aditya Prakash, Saurabh Gupta.
Look Ma, No Hands! Agent-Environment Factorization of Egocentric Videos.
Arxiv Preprint.
@inproceedings{chang2023look,
title={Look Ma, No Hands! Agent-Environment Factorization of Egocentric Videos},
author={Matthew Chang and Aditya Prakash and Saurabh Gupta},
year={2023},
booktitle={NeurIPS}},
}
|
Acknowledgements
We thank Ruisen Tu and Advait Patel for their help with collecting segmentation annotations for the claw and the robot end-effector. We also thank Arjun Gupta, Erin Zhang, Shaowei Liu, and Joseph Lubars for their feedback on the manuscript. This material is based upon work supported by NSF (IIS2007035), DARPA (Machine Common Sense program), NASA (80NSSC21K1030), an Amazon Research Award, an NVidia Academic Hardware Grant, and the NCSA Delta System (supported by NSF OCI 2005572 and the State of Illinois)
Website template from here, here, and here.
|